Sort Merge Bucket
Sort Merge Bucket (SMB) is a technique for writing data to file system in deterministic file locations, sorted according to some pre-determined key, so that it can later be read in as key groups with no shuffle required. Since each element is assigned a file destination (bucket) based on a hash of its join key, we can use the same technique to cogroup multiple Sources as long as they’re written using the same key and hashing scheme.
For example, given these input records, and SMB write will first extract the key, assign the record to a bucket, sort values within the bucket, and write these values to a corresponding file.
| Input | Key | Bucket | File Assignment |
|---|---|---|---|
| {key:“b”, value: 1} | “b” | 0 | bucket-00000-of-00002.avro |
| {key:“b”, value: 2} | “b” | 0 | bucket-00000-of-00002.avro |
| {key:“a”, value: 3} | “a” | 1 | bucket-00001-of-00002.avro |
Two sources can be joined by opening file readers on corresponding buckets of each source and merging key-groups as we go.
What are SMB transforms?
scio-smb provides three PTransforms, as well as corresponding Scala API bindings, for SMB operations:
-
SortedBucketSinkwrites data to file system in SMB format. Scala APIs (see:SortedBucketSCollection):-
SCollection[T: Coder]#saveAsSortedBucket
source
val accountWriteTap = sc .parallelize(250 until 750) .map { i => Account .newBuilder() .setId(i % 100) .setName(s"name$i") .setType(s"type${i % 5}") .setAmount(Random.nextDouble() * 1000) .build() } .saveAsSortedBucket( ParquetAvroSortedBucketIO .write[Integer, Account](classOf[Integer], "id", classOf[Account]) .to(args("accounts")) .withSorterMemoryMb(128) .withTempDirectory(sc.options.getTempLocation) .withConfiguration( ParquetConfiguration.of(ParquetOutputFormat.BLOCK_SIZE -> 512 * 1024 * 1024) ) .withHashType(HashType.MURMUR3_32) .withFilenamePrefix("part") // Default is "bucket" .withNumBuckets(1) .withNumShards(1) )Note the use of
Integerfor parameterized key type instead of a ScalaInt. The key class must have a Coder available in the default Beam (Java) coder registry.Also note that the number of buckets specified must be a power of 2. This allows sources of different bucket sizes to still be joinable.
-
-
SortedBucketSourcereads data that has been written to file system usingSortedBucketSinkinto a collection ofCoGbkResults. Scala APIs (see:SortedBucketScioContext):ScioContext#sortMergeGroupByKey(1 source)ScioContext#sortMergeJoin(2 sources)ScioContext#sortMergeCoGroup(1-22 sources)
Note that each
TupleTagused to create theSortedBucketIO.Reads needs to have a unique Id.source
sc.sortMergeJoin( classOf[Integer], ParquetAvroSortedBucketIO .read(new TupleTag[GenericRecord]("users"), SortMergeBucketExample.UserDataSchema) .withProjection( SchemaBuilder .record("UserProjection") .fields .requiredInt("userId") .requiredInt("age") .endRecord ) // Filter at the Parquet IO level to users under 50 // Filtering at the IO level whenever possible, as it reduces total bytes read .withFilterPredicate(FilterApi.lt(FilterApi.intColumn("age"), Int.box(50))) // Filter at the SMB Cogrouping level to a single record per user // Filter at the Cogroup level if your filter depends on the materializing key group .withPredicate((xs, _) => xs.size() == 0) .from(args("users")), ParquetTypeSortedBucketIO .read(new TupleTag[AccountProjection]("accounts")) .from(args("accounts")), TargetParallelism.max() ).map { case (_, (userData, account)) => (userData.get("age").asInstanceOf[Int], account.amount) }.groupByKey .mapValues(amounts => amounts.sum / amounts.size) .saveAsTextFile(args("output")) -
SortedBucketTransformreads data that has been written to file system usingSortedBucketSink, transforms eachCoGbkResultusing a user-supplied function, and immediately rewrites them using the same bucketing scheme. Scala APIs (see:SortedBucketScioContext):-
ScioContext#sortMergeTransform(1-22 sources)
Note that each
TupleTagused to create theSortedBucketIO.Reads needs to have a unique Id.source
sc.sortMergeTransform( classOf[Integer], ParquetAvroSortedBucketIO .read(new TupleTag[GenericRecord]("users"), SortMergeBucketExample.UserDataSchema) // Filter at the Parquet IO level to users under 50 .withFilterPredicate(FilterApi.lt(FilterApi.intColumn("age"), Int.box(50))) .from(args("users")), ParquetTypeSortedBucketIO .read(new TupleTag[AccountProjection]("accounts")) .from(args("accounts")), TargetParallelism.auto() ).to( ParquetTypeSortedBucketIO .transformOutput[Integer, CombinedAccount]("id") .to(args("output")) ).via { case (key, (users, accounts), outputCollector) => val sum = accounts.map(_.amount).sum users.foreach { user => outputCollector.accept( CombinedAccount(key, user.get("age").asInstanceOf[Integer], sum) ) } } -
What kind of data can I write using SMB?
SMB writes are supported for multiple formats:
- Avro (GenericRecord and SpecificRecord) when also depending on
scio-avro. - JSON
- Parquet when also depending on
scio-parquet - Tensorflow when also depending on
scio-tensorflow
Secondary keys
Since Scio 0.12.0.
A single key group may be very large and the implementation of SMB requires either handling the elements of the key group iteratively or loading the entire key group into memory. In the case where a secondary grouping or sorting is required, this can be prohibitive in terms of memory and/or wasteful when multiple downstream pipelines do the same grouping. For example, a SMB dataset might be keyed by user_id but many downstreams want to group by the tuple of (user_id, artist_id).
Secondary SMB keys enable this use-case by sorting pipeline output by the hashed primary SMB key as described above, then additionally sorting the output for each key by the secondary SMB key. When key groups are read by a downstream pipeline it may read either the entire (primary) key group or the subset of elements belonging to the (primary key, secondary key) tuple.
A dataset may therefore add a secondary key and remain compatible with any downstream readers which expect only a primary key.
To write with a secondary key, the additional key class and path must be provided:
source.saveAsSortedBucket(
ParquetAvroSortedBucketIO
.write[Integer, String, Account](
// primary key class and field
classOf[Integer],
"id",
// secondary key class and field
classOf[String],
"type",
classOf[Account]
)
.to(args("accounts"))
)
To read with a secondary key, the additional key class must be provided:
sourcesc.sortMergeGroupByKey(
classOf[String], // primary key class
classOf[String], // secondary key class
ParquetAvroSortedBucketIO
.read(new TupleTag[Account]("account"), classOf[Account])
.from(args("accounts"))
).map { case ((primaryKey, secondaryKey), elements) =>
// ...
}
Corresponding secondary-key-enabled variants of sortMergeJoin, sortMergeCogroup, and sortMergeTransform are also included.
Null keys
If the key field of one or more PCollection elements is null, those elements will be diverted into a special bucket file, bucket-null-keys.avro. This file will be ignored in SMB reads and transforms and must be manually read by a downstream user.
Avro String keys
As of Scio 0.14.0, Avro CharSequence are backed by String instead of default Utf8. With previous versions you may encounter the following when using Avro CharSequence keys:
Cause: java.lang.ClassCastException: class org.apache.avro.util.Utf8 cannot be cast to class java.lang.String
[info] at org.apache.beam.sdk.coders.StringUtf8Coder.encode(StringUtf8Coder.java:37)
[info] at org.apache.beam.sdk.extensions.smb.BucketMetadata.encodeKeyBytes(BucketMetadata.java:222)
You’ll have to either recompile your avro schema using String type, or add the GenericData.StringType.String property to your Avro schema with setStringType
Parquet
SMB supports Parquet reads and writes in both Avro and case class formats.
As of Scio 0.14.0 and above, Scio supports specific record logical types in parquet-avro out of the box.
When using generic record, you have to manually supply a data supplier in your Parquet Configuration parameter. See Logical Types in Parquet for more information.
Tuning parameters for SMB transforms
numBuckets/numShards
SMB reads should be more performant and less resource-intensive than regular joins or groupBys. However, SMB writes are more expensive than their regular counterparts, since they involve an extra group-by (bucketing) and sorting step. Additionally, non-SMB writes (i.e. implementations of FileBasedSink) use hints from the runner to determine an optimal number of output files. Unfortunately, SMB doesn’t have access to those runtime hints; you must specify the number of buckets and shards as static values up front.
In SMB, buckets correspond to the hashed value of the SMB key % a given power of 2. A record with a given key will always be hashed into the same bucket. On the file system, buckets consist of one or more sharded files in which records are randomly assigned per-bundle. Two records with the same key may end up in different shard files within a bucket.
- A good starting point is to look at your output data as it has been written by a non-SMB sink, and pick the closest power of 2 as your initial
numBucketsand setnumShardsto 1. - If you anticipate having hot keys, try increasing
numShardsto randomly split data within a bucket. numBuckets*numShards= total # of files written to disk.
sorterMemoryMb
If your job gets stuck in the sorting phase (since the GroupByKey and SortValues transforms may get fused–you can reference the Counters SortedBucketSink-bucketsInitiatedSorting and SortedBucketSink-bucketsCompletedSorting to get an idea of where your job fails), you can increase sorter memory (default is 1024MB, or 128MB for Scio <= 0.9.0):
data.saveAsSortedBucket(
AvroSortedBucketIO
.write[K, V](classOf[K], "keyField", classOf[V])
.to(...)
.withSorterMemoryMb(256)
)
The amount of data each external sorter instance needs to handle is total output size / numBuckets
/ numShards, and when this exceeds sorter memory, the sorter will spill to disk. n1-standard workers has 3.75GB RAM per CPU, so 1GB sorter memory is a decent default, especially if the output files are kept under that size. If you have to spill to disk, note that worker disk IO depends on disk type, size, and worker number of CPUs.
See specifying pipeline execution parameters for more details, e.g. --workerMachineType, --workerDiskType, and --diskSizeGb. Also read more about machine types and block storage performance
Parallelism
The SortedBucketSource API accepts an optional TargetParallelism parameter to set the desired parallelism of the SMB read operation. For a given set of sources, targetParallelism can be set to any number between the least and greatest numbers of buckets among sources. This can be dynamically configured using TargetParallelism.min() or TargetParallelism.max(), which at graph construction time will determine the least or greatest amount of parallelism based on sources.
Alternately, TargetParallelism.of(Integer value) can be used to statically configure a custom value, or {@link TargetParallelism#auto()} can be used to let the runner decide how to split the SMB read at runtime based on the combined byte size of the inputs–this is also the default behavior if TargetPallelism is left unspecified.
If no value is specified, SMB read operations will use Auto parallelism.
When selecting a target parallelism for your SMB operation, there are tradeoffs to consider:
- Minimal parallelism means a fewer number of workers merging data from potentially many buckets. For example, if source A has 4 buckets and source B has 64, a minimally parallel SMB read would have 4 workers, each one merging 1 bucket from source A and 16 buckets from source B. This read may have low throughput.
- Maximal parallelism means that each bucket is read by at least one worker. For example, if source A has 4 buckets and source B has 64, a maximally parallel SMB read would have 64 workers, each one merging 1 bucket from source B and 1 bucket from source A, replicated 16 times. This may have better throughput than the minimal example, but more expensive because every key group from the replicated sources must be re-hashed to avoid emitting duplicate records.
- A custom parallelism in the middle of these bounds may be the best balance of speed and computing cost.
- Auto parallelism is more likely to pick an ideal value for most use cases. If its performance is worse than expected, you can look up the parallelism value it has computed and try a manual adjustment. Unfortunately, since it’s determined at runtime, the computed parallelism value can’t be added to the pipeline graph through
DisplayData. Instead, you’ll have to check the worker logs to find out which value was selected. When using Dataflow, you can do this in the UI by clicking on the SMB transform box, and searching the associated logs for the textParallelism was adjusted. For example, in this case the value is 1024: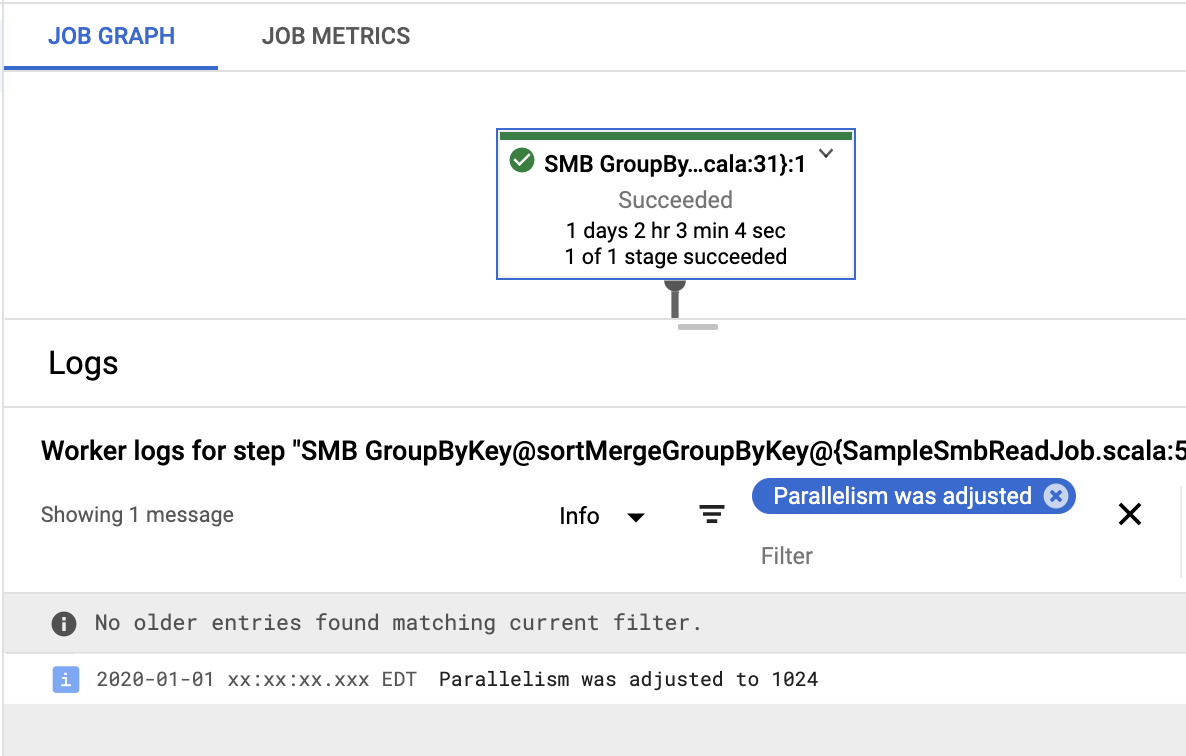
From there, you can try increasing or decreasing the parallelism by specifying a different
TargetParallelismparameter to your SMB read. Often auto-parallelism will select a low value and usingTargetParallelism.max()can help.
Read buffering
Performance can suffer when reading an SMB source across many partitions if the total number of files (numBuckets * numShards * numPartitions) is too large (on the order of hundreds of thousands to millions of files). We’ve observed errors and timeouts as a result of too many simultaneous filesystem connections. To that end, we’ve added two PipelineOptions to Scio 0.10.3, settable either via command-line args or using SortedBucketOptions directly.
--sortedBucketReadBufferSize(default: 10000): an Integer that determines the number of elements to read and buffer from each file at a time. For example, by default, each file will have 10,000 elements read and buffered into an in-memory array at worker startup. Then, the sort-merge algorithm will request them one at a time as needed. Once 10,000 elements have been requested, the file will buffer the next 10,000.Note: this can be quite memory-intensive and require bumping the worker memory. If you have a small number of files, or don’t need this optimization, you can turn it off by setting
--sortedBucketReadBufferSize=0.--sortedBucketReadDiskBufferMb(default: unset): an Integer that, if set, will force each worker to actually copy the specified # of megabytes from the remote filesystem into the worker’s local temp directory, rather than streaming directly from FS. This caching is done eagerly: each worker will read as much as it can of each file in the order they’re requested, and more space will be freed up once a file is fully read. Note that this is a per worker limit.
Testing
As of Scio 0.14, mocking data for SMB transforms is supported in the com.spotify.scio.testing.JobTest framework. Prior to Scio 0.14, you can test using real data written to local temp files.
Testing SMB in JobTest
Scio 0.14 and above support testing SMB reads, writes, and transforms using SmbIO.
Consider the following sample job that contains an SMB read and write:
import org.apache.beam.sdk.extensions.smb.ParquetAvroSortedBucketIO
import org.apache.beam.sdk.values.TupleTag
import com.spotify.scio._
import com.spotify.scio.avro.Account
import com.spotify.scio.values.SCollection
import com.spotify.scio.smb._
object SmbJob {
def main(cmdLineArgs: Array[String]): Unit = {
val (sc, args) = ContextAndArgs(cmdLineArgs)
// Read
sc.sortMergeGroupByKey(
classOf[Integer],
ParquetAvroSortedBucketIO
.read(new TupleTag[Account](), classOf[Account])
.from(args("input"))
)
// Write
val writeData: SCollection[Account] = ???
writeData.saveAsSortedBucket(
ParquetAvroSortedBucketIO
.write(classOf[Integer], "id", classOf[Account])
.to(args("output"))
)
sc.run().waitUntilDone()
}
}
A JobTest can be wired in using SmbIO inputs and outputs. SmbIO is typed according to the record type and the SMB key type, and the SMB key function is required to construct it.
import com.spotify.scio.smb.SmbIO
import com.spotify.scio.testing.PipelineSpec
class SmbJobTest extends PipelineSpec {
"SmbJob" should "work" in {
val smbInput: Seq[Account] = ???
JobTest[SmbJob.type]
.args("--input=gs://input", "--output=gs://output")
// Mock .sortMergeGroupByKey
.input(SmbIO[Int, Account]("gs://input", _.getId), smbInput)
// Mock .saveAsSortedBucket
.output(SmbIO[Int, Account]("gs://output", _.getId)) { output =>
// Assert on output
}
.run()
}
}
SMB Transforms can be mocked by combining input and output SmbIOs:
// Scio job
object SmbTransformJob {
def main(cmdLineArgs: Array[String]): Unit = {
val (sc, args) = ContextAndArgs(cmdLineArgs)
sc.sortMergeTransform(
classOf[Integer],
ParquetAvroSortedBucketIO
.read(new TupleTag[Account](), classOf[Account])
.from(args("input"))
).to(
ParquetAvroSortedBucketIO
.transformOutput[Integer, Account](classOf[Integer], "id", classOf[Account])
.to(args("output"))
).via { case (key, grouped, outputCollector) =>
val output: Account = ???
outputCollector.accept(output)
}
sc.run().waitUntilDone()
}
}
// Job test
class SmbTransformJobTest extends PipelineSpec {
"SmbTransformJob" should "work" in {
val smbinput: Seq[Account] = ???
JobTest[SmbTransformJob.type]
.args("--input=gs://input", "--output=gs://output")
// Mock SMB Transform input
.input(SmbIO[Int, Account]("gs://input", _.getId), smbinput)
// Mock SMB Transform output
.output(SmbIO[Int, Account]("gs://output", _.getId)) { output =>
// Assert on output
}
.run()
}
}
See SortMergeBucketExampleTest for complete JobTest examples.
Testing SMB using local file system
Using the JobTest framework for SMB reads, writes, and transforms is recommended, as it eliminates the need to manage local files and Taps. However, there are a few cases where performing real reads and writes is advantageous:
- If you want to assert on SMB Predicates/Parquet FilterPredicates in reads, as these are skipped in JobTest
- If you want to assert on written metadata
- If you want to test schema evolution compatibility (i.e. writing using an updated record schema and reading using the original schema), or on projected schema compatability (i.e. using a case class projection to read Parquet data written with an Avro schema)
Scio 0.14.0 and above automatically return Taps for SMB writes and transforms, and can materialize SMB reads into Taps:
import com.spotify.scio.io.ClosedTap
// Scio job
object SmbRealFilesJob {
def write(sc: ScioContext, output: String): ClosedTap[Account] = {
val writeData: SCollection[Account] = ???
writeData.saveAsSortedBucket(
ParquetAvroSortedBucketIO
.write(classOf[Integer], "id", classOf[Account])
.to(output)
)
}
def read(sc: ScioContext, input: String): SCollection[(Integer, Iterable[Account])] = {
sc.sortMergeGroupByKey(
classOf[Integer],
ParquetAvroSortedBucketIO
.read(new TupleTag[Account](), classOf[Account])
.from(input)
)
}
}
// Unit test
import java.nio.file.Files
class SmbLocalFilesTest extends PipelineSpec {
"SmbRealFilesJob" should "write and read data" in {
val dir = Files.createTempDirectory("smb").toString
// Test write
val (_, writtenData) = runWithOutput { sc =>
SmbRealFilesJob.write(sc, dir)
}
// Assert on actual written output
writtenData.value should have size 100
// Test read in separate ScioContext
val (_, groupedData) = runWithLocalOutput { sc =>
SmbRealFilesJob.read(sc, dir)
}
// Assert on actual read result
groupedData should have size 50
}
}
In addition to JobTest examples, see SortMergeBucketExampleTest for complete SMB Tap examples.